Video Link on Youtube: An Introduction to Graph Neural Networks: Models and Applications
Intro
Distributed Vector Representations

From one-hot -> multiply with embedding matrix and get distributed rep.
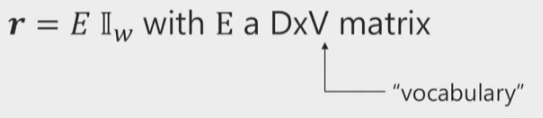
Graph Notation Basics
- Nodes/Vertices
- Edges
- $G=(V,E)$
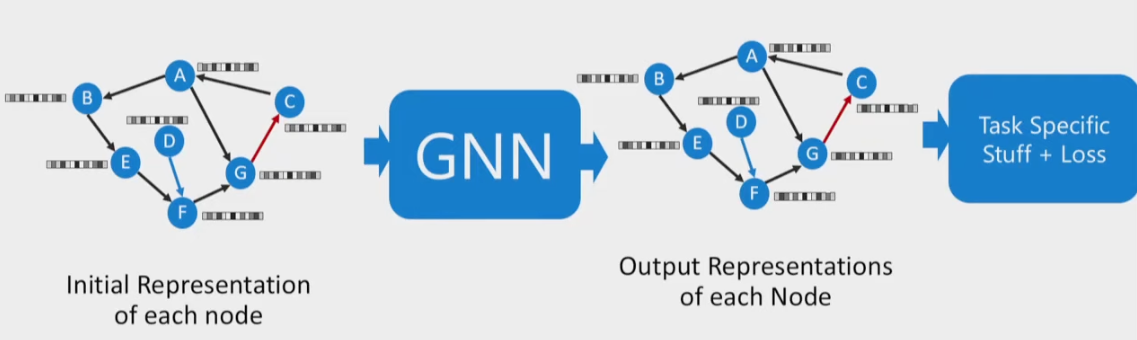
Graph Neural Network
By training, each node’s vector contains information relative to the whole graph, instead of the initial representation.
-
GNNs Synchronous Message Passing (All-to-All)
-
Output:
- Node selection
- Node classification
- Graph classification
Gated GNNs
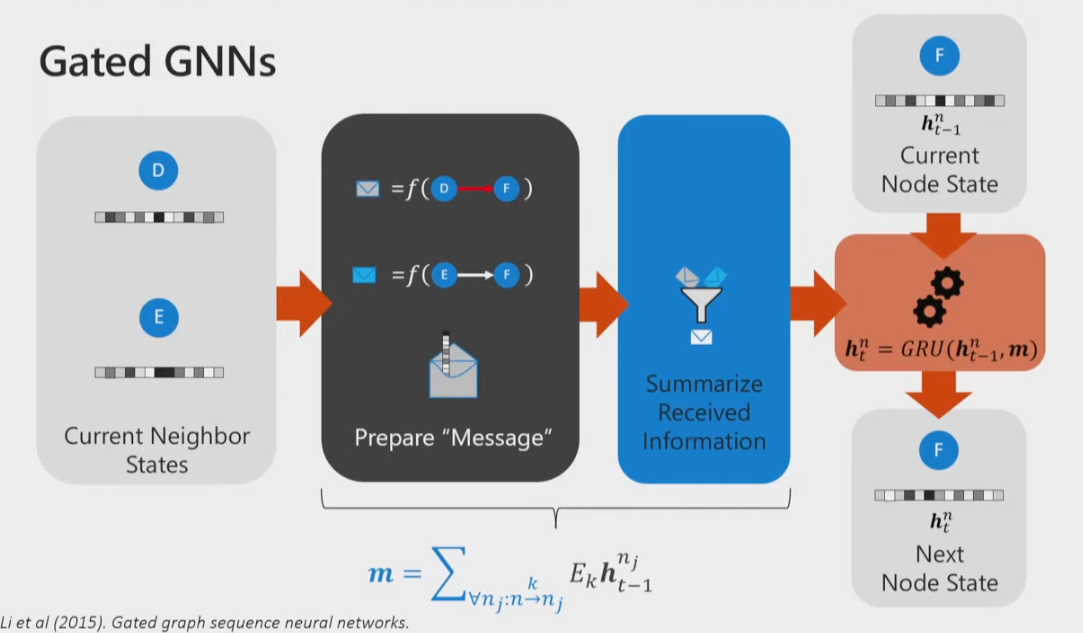
GRU: Gated Recurrent Network
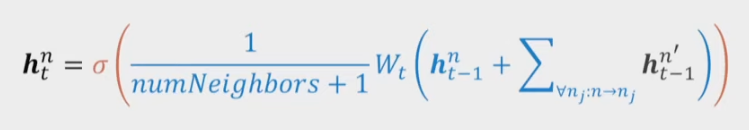
- permutation invariant -> Sum
GCN
Trick 1: backwards Edges

- For each forward edge, add a backward edge
Graph Notations - Adjacency Matrix
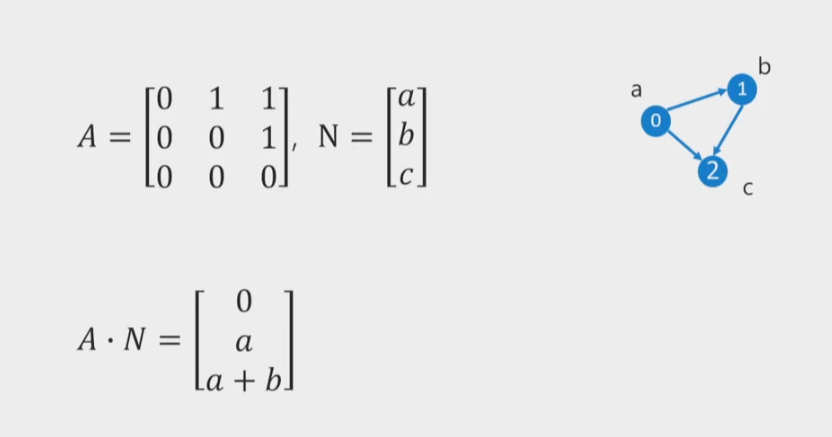
GGNN as Matrix Operation

Express as code
- einsum
C = np.einsum('bd,qd->bq', A, B)
D = np.einsum('abs,be,abq->cqe',A,B,C)
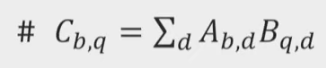
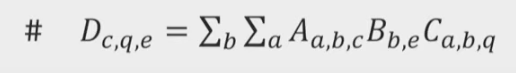
def GGNN(initial_node_states, adj):
node_states = initial_node_states #[N,D]
for i in range(num_steps):
messages = {}
for k in range(num_message_types):
message[k] = einsum('nd,dm-nm', edge_transform, node_states) # [N, M]
received_messages = zeros(num_nodes, M) # (N, M)
for k in range(num_message_types):
received_messages += einsum('nm,ml->lm', message[k], adj[k])
node_states = GRU(node_states, received_messages)
return node_states
Notes: The adjancency matrix can be very large and sparse
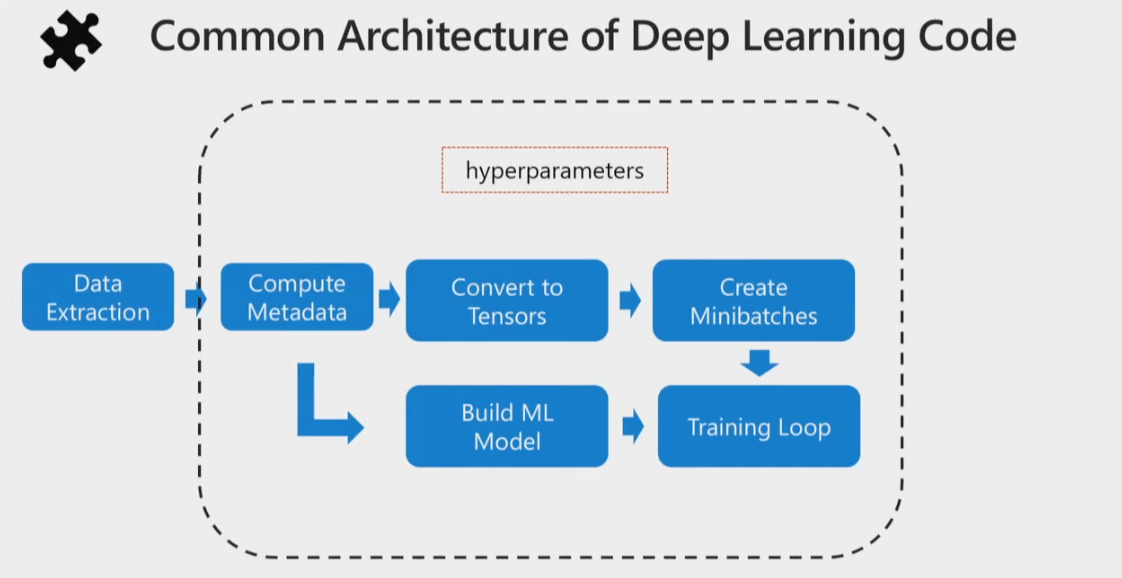
Common Arch of Deep Learning Code